Firefox’s crash reporter is hopefully not something that most users experience often. However, it is still a very important component of Firefox, as it is integral in providing insight into the most visible bugs: those which crash the main process. These bugs offer the worst user experience (since the entire application must close), so fixing them is a very high priority. Other types of crashes, such as content (tab) crashes, can be handled by the browser and reported gracefully, sometimes without the user being aware that an issue occurred at all. But when the main browser process comes to a halt, we need another separate application to gather information about the crash and interact with the user.
This post details the approach we have taken to rewrite the crash reporter in Rust. We discuss the reasoning behind this rewrite, what makes the crash reporter a unique application, the architecture we used, and some details of the implementation.
Why Rewrite?
Even though it is important to properly handle main process crashes, the crash reporter hasn’t received significant development in a while (aside from development to ensure that crash reports and telemetry continue to reliably be delivered)! It has long been stuck in a local maximum of “good enough” and “scary to maintain”: it features 3 individual GUI implementations (for Windows, GTK+ for Linux, and macOS), glue code abstracting a few things (mostly in C++, and Objective-C for macOS), a binary blob produced by obsoleted Apple development tools, and no test suite. Because of this, there is a backlog of features and improvements which haven’t been acted on.
We’ve recently had a number of successful pushes to decrease crash rates (including both big leaps and many small bug fixes), and the crash reporter has functioned well enough for our needs during this time. However, we’ve reached an inflection point where improving the crash reporter would provide valuable insight to enable us to decrease the crash rate even further. For the reasons previously mentioned, improving the current codebase is difficult and error-prone, so we deemed it appropriate to rewrite the application so we can more easily act on the feature backlog and improve crash reports.
Like many components of Firefox, we decided to use Rust for this rewrite to produce a more reliable and maintainable program. Besides the often-touted memory safety built into Rust, its type system and standard library make reasoning about code, handling errors, and developing cross-platform applications far more robust and comprehensive.
Crash Reporting is an Edge Case
There are a number of features of the crash reporter which make it quite unique, especially compared to other components which have been ported to Rust. For one thing, it is a standalone, individual program; basically no other components of Firefox are used in this way. Firefox itself launches many processes as a means of sandboxing and insulating against crashes, however these processes all talk to one another and have access to the same code base.
The crash reporter has a very unique requirement: it must use as little as possible of the Firefox code base, ideally none! We don’t want it to rely on code which may be buggy and cause the reporter itself to crash. Using a completely independent implementation ensures that when a main process crash does occur, the cause of that crash won’t affect the reporter’s functionality as well.
The crash reporter also necessarily has a GUI. This alone may not separate it from other Firefox components, but we can’t leverage any of the cross-platform rendering goodness that Firefox provides! So we need to implement a cross-platform GUI independent of Firefox as well. You might think we could reach for an existing cross-platform GUI crate, however we have a few reasons not to do so.
- We want to minimize the use of external code: to improve crash reporter reliability (which is paramount), we want it to be as simple and auditable as possible.
- Firefox vendors all dependencies in-tree, so we are hesitant to bring in large dependencies (GUI libraries are likely pretty sizable).
- There are only a few third-party crates that provide a native OS look and feel (or actually use native GUI APIs): it’s desirable for the crash reporter to have a native feel to be familiar to users and take advantage of accessibility features.
So all of this is to say that third-party cross-platform GUI libraries aren’t a favorable option.
These requirements significantly narrow the approach that can be used.
Building a GUI View Abstraction
In order to make the crash reporter more maintainable (and make it easier to add new features in the future), we want to have as minimal and generic platform-specific code as possible. We can achieve this by using a simple UI model that can be converted into native GUI code for each platform. Each UI implementation will need to provide two methods (over arbitrary platform-specific &self data):
/// Run a UI loop, displaying all windows of the application until it terminates.
fn run_loop(&self, app: model::Application)
/// Invoke a function asynchronously on the UI loop thread.
fn invoke(&self, f: model::InvokeFn)
The run_loop function is pretty self-explanatory: the UI implementation takes an Application model (which we’ll discuss shortly) and runs the application, blocking until the application is complete. Conveniently, our target platforms generally have similar assumptions around threading: the UI runs in a single thread and typically runs an event loop which blocks on new events until an event signaling the end of the application is received.
There are some cases where we’ll need to run a function on the UI thread asynchronously (like displaying a window, updating a text field, etc). Since run_loop blocks, we need the invoke method to define how to do this. This threading model will make it easy to use the platform GUI frameworks: everything calling native functions will occur on a single thread (the main thread in fact) for the duration of the program.
This is a good time to be a bit more specific about exactly what each UI implementation will look like. We’ll discuss pain points for each later on. There are 4 UI implementations:
- A Windows implementation using the Win32 API.
- A macOS implementation using Cocoa (AppKit and Foundation frameworks).
- A Linux implementation using GTK+ 3 (the “+” has since been dropped in GTK 4, so henceforth I’ll refer to it as “GTK”). Linux doesn’t provide its own GUI primitives, and we already ship GTK with Firefox on Linux to make a modern-feeling GUI, so we can use it for the crash reporter, too. Note that some platforms that aren’t directly supported by Mozilla (like BSDs) use the GTK implementation as well.
- A testing implementation which will allow tests to hook into a virtual UI and poke things (to simulate interactions and read state).
One last detail before we dive in: the crash reporter (at least right now) has a pretty simple GUI. Because of this, an explicit non-goal of the development was to create a separate Rust GUI crate. We wanted to create just enough of an abstraction to cover the cases we needed in the crash reporter. If we need more controls in the future, we can add them to the abstraction, but we avoided spending extra cycles to fill out every GUI use case.
Likewise, we tried to avoid unnecessary development by allowing some tolerance for hacks and built-in edge cases. For example, our model defines a Button as an element which contains an arbitrary element, but actually supporting that with Win32 or AppKit would have required a lot of custom code, so we special case on a Button containing a Label (which is all we need right now, and an easy primitive available to us). I’m happy to say there aren’t really many special cases like that at all, but we are comfortable with the few that were needed.
The UI Model
Our model is a declarative structuring of concepts mostly present in GTK. Since GTK is a mature library with proven high-level UI concepts, this made it appropriate for our abstraction and made the GTK implementation pretty simple. For instance, the simplest way that GTK does layout (using container GUI elements and per-element margins/alignments) is good enough for our GUI, so we use similar definitions in the model. Notably, this “simple” layout definition is actually somewhat high-level and complicates the macOS and Windows implementations a bit (but this tradeoff is worth the ease of creating UI models).
The top-level type of our UI model is Application. This is pretty simple: we define an Application as a set of top-level Windows (though our application only has one) and whether the current locale is right-to-left. We inspect Firefox resources to use the same locale that Firefox would, so we don’t rely on the native GUI’s locale settings.
As you might expect, each Window contains a single root element. The rest of the model is made up of a handful of typical container and primitive GUI elements:
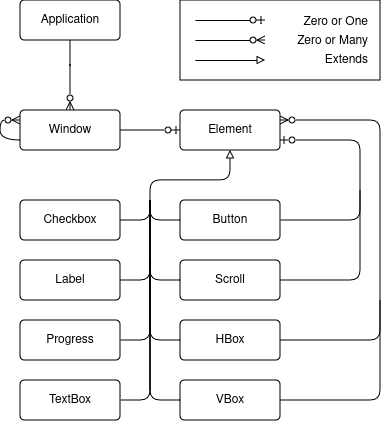
The crash reporter only needs 8 types of GUI elements! And really, Progress is used as a spinner rather than indicating any real progress as of right now, so it’s not strictly necessary (but nice to show).
Rust does not explicitly support the object-oriented concept of inheritance, so you might be wondering how each GUI element “extends” Element. The relationship represented in the picture is somewhat abstract; the implemented Element looks like:
pub struct Element {
pub style: ElementStyle,
pub element_type: ElementType
}
where ElementStyle contains all the common properties of elements (alignment, size, margin, visibility, and enabled state), and ElementType is an enum containing each of the specific GUI elements as variants.
Building the Model
The model elements are all intended to be consumed by the UI implementations; as such, almost all of the fields have public visibility. However, as a means of having a separate interface for building elements, we define an ElementBuilder<T> type. This type has methods that maintain assertions and provide convenience setters. For instance, many methods accept parameters that are impl Into<MemberType>, some methods like margin() set multiple values (but you can be more specific with margin_top()), etc.
There is a general impl<T> ElementBuilder<T> which provides setters for the various ElementStyle properties, and then each specific element type can also provide their own impl ElementBuilder<SpecificElement> with additional properties unique to the element type.
We combine ElementBuilder<T> with the final piece of the puzzle: a ui! macro. This macro allows us to write our UI in a declarative manner. For example, it allows us to write:
let details_window = ui! {
Window title("Crash Details") visible(show_details) modal(true) hsize(600) vsize(400)
halign(Alignment::Fill) valign(Alignment::Fill)
{
VBox margin(10) spacing(10) halign(Alignment::Fill) valign(Alignment::Fill) {
Scroll halign(Alignment::Fill) valign(Alignment::Fill) {
TextBox content(details) halign(Alignment::Fill) valign(Alignment::Fill)
},
Button halign(Alignment::End) on_click(move || *show_details.borrow_mut() = false)
{
Label text("Ok")
}
}
}
};
The implementation of ui! is fairly simple. The first identifier provides the element type and an ElementBuilder<T> is created. After that, the remaining method-call-like syntax forms are called on the builder (which is mutable).
Optionally, a final set of curly braces indicate that the element has children. In that case, the macro is recursively called to create them, and add_child is called on the builder with the result (so we just need to make sure a builder has an add_child method). Ultimately the syntax transformation is pretty simple, but I believe that this macro is a little bit more than just syntax sugar: it makes reading and editing the UI a fair bit clearer, since the hierarchy of elements is represented in the syntax. Unfortunately a downside is that there’s no way to support automatic formatting of such macro DSLs, so developers will need to maintain a sane formatting.
So now we have a model defined and a declarative way of building it. But we haven’t discussed any dynamic runtime behaviors here. In the above example, we see an on_click handler being set on a Button. We also see things like the Window’s visible property being set to a show_details value which is changed when on_click is pressed. We hook into this declarative UI to change or react to events at runtime using a set of simple data binding primitives with which UI implementations can interact.
Many GUI frameworks nowadays (both for Rust and other languages) have been built with the “diffing element trees” architecture (think React), where your code is (at least mostly) functional and side-effect-free and produces the GUI view as a function of the current state. This approach has its tradeoffs: for instance, it makes complicated, stateful alterations of the layout very simple to write, understand, and maintain, and encourages a clean separation of model and view! However since we aren’t writing a framework, and our application is and will remain fairly simple, the benefits of such an architecture were not worth the additional development burden. Our implementation is more similar to the MVVM architecture:
- the model is, well, the model discussed here;
- the views are the various UI implementations; and
- the viewmodel is (loosely, if you squint) the collection of data bindings.
Data Binding
There are a few types which we use to declare dynamic (runtime-changeable) values. In our UI, we needed to support a few different behaviors:
- triggering events, i.e., what happens when a button is clicked,
- synchronized values which will mirror and notify of changes to all clones, and
- on-demand values which can be queried for the current value.
On-demand values are used to get textbox contents rather than using a synchronized value, in an effort to avoid implementing debouncing in each UI. It may not be terribly difficult to do so, but it also wasn’t difficult to support the on-demand implementation.
As a means of convenience, we created a Property type which encompasses the value-oriented fields as well. A Property<T> can be set to either a static value (T), a synchronized value (Synchronized<T>), or an on-demand value (OnDemand<T>). It supports an impl From for each of these, so that builder methods can look like fn my_method(&mut self, value: impl Into<Property<T>>) allowing any supported value to be passed in a UI declaration.
We won’t discuss the implementation in depth (it’s what you’d expect), but it’s worth noting that these are all Clone to easily share the data bindings: they use Rc (we don’t need thread safety) and RefCell as necessary to access callbacks.
In the example from the last section, show_details is a Synchronized<bool> value. When it changes, the UI implementations change the associated window visibility. The Button on_click callback sets the synchronized value to false, hiding the window (note that the details window used in this example is never closed, it is just shown and hidden).
In a former iteration, data binding types had a lifetime parameter which specified the lifetime for which event callbacks were valid. While we were able to make this work, it greatly complicated the code, especially because there’s no way to communicate the correct covariance of the lifetime to the compiler, so there was additional unsafe code transmuting lifetimes (though it was contained as an implementation detail). These lifetimes were also infectious, requiring some of the complicated semantics regarding their safety to be propagated into the model types which stored Property fields.
Much of this was to avoid cloning values into the callbacks, but changing these types to all be Clone and store static-lifetime callbacks was worth making the code far more maintainable.
Threading and Thread Safety
The careful reader might remember that we discussed how our threading model involves interacting with the UI implementations only on the main thread. This includes updating the data bindings, since the UI implementations might have registered callbacks on them! While we could run everything in the main thread, it’s generally a much better experience to do as much off of the UI thread as possible, even if we don’t do much that’s blocking (though we will be blocking when we send crash reports). We want our business logic to default to being off of the main thread so that the UI doesn’t ever freeze. We can guarantee this with some careful design.
The simplest way to guarantee this behavior is to put all of the business logic in one (non-Clone, non-Sync) type (let’s call it Logic) and construct the UI and UI state (like Property values) in another type (let’s call it UI). We can then move the Logic value into a separate thread to guarantee that UI can’t interact with Logic directly, and vice versa. Of course we do need to communicate sometimes! But we want to ensure that this communication will always be delegated to the thread which owns the values (rather than the values directly interacting with each other).
We can accomplish this by creating an enqueuing function for each type and storing that in the opposite type. Such a function will be passed boxed functions to run on the owning thread that get a reference to the owned type (e.g., Box<dyn FnOnce(&T) + Send + 'static>). This is simple to create: for the UI thread, it is just the UI implementation’s invoke method which we briefly discussed previously. The Logic thread does nothing but run a loop which will get these functions and run them on the owned value (we just enqueue and pass them using an mpsc::channel). Now each type can asynchronously call methods on the other with the guarantee that they’ll be run on the correct thread.
In a former iteration, a more complicated scheme was used with thread-local storage and a central type which was responsible for both creating threads and delegating the functions. But with such a basic use case as two threads delegating between each other, we were able to distill this to the essential aspects needed, greatly simplifying the code.
Localization
One nice benefit of this rewrite is that we could bring the localization of the crash reporter up to speed with our modern tooling. In almost every other part of Firefox, we use fluent to handle localization. Using fluent in the crash reporter makes the experience of localizers more uniform and predictable; they do not need to understand more than one localization system (the crash reporter was one of the last holdouts of the old system). It was very easy to use in the new code, with just a bit of extra code to extract the localization files from the Firefox installation when the crash reporter is run. In the worst case scenario where we can’t find or access these files, we have the en-US definitions directly bundled in the crash reporter binary.
The UI Implementations
We won’t go into much detail about the implementations, but it’s worth talking about each a bit.
Linux (GTK)
The GTK implementation is probably the most straightforward and succinct. We use bindgen to generate Rust bindings to the GTK functions we need (avoiding vendoring any external crates). Then we simply call all of the corresponding GTK functions to set up the GTK widgets as described in the model (remember, the model was made to mirror some of the GTK concepts).
Since GTK is somewhat modern and meant to be written by humans (not automated tools like some of the other platforms), there weren’t really any pain points or unusual behaviors that needed to be addressed.
We have a handful of nice features to improve memory safety and correctness. A set of traits makes it easy to attach owned data to GObjects (ensuring data remains valid and is properly dropped when the GObject is destroyed), and a few macros set up the glue code between GTK signals and our data binding types.
Windows (Win32)
The Windows implementation may have been the most difficult to write, since Win32 GUIs are very rarely written nowadays and the API shows its age. We use the windows-sys crate to access bindings to the API (which was already vendored in the codebase for many other Windows API uses). This crate is generated directly from Windows function metadata (by Microsoft), but otherwise its bindings aren’t terribly different from what bindgen might have produced (though they are likely a bit more accurate).
There were a number of hurdles to overcome. For one thing, the Win32 API doesn’t provide any layout primitives, so the high-level layout concepts we use (which allow graceful resize/repositioning) had to be implemented manually. There’s also quite a few extra API calls just to get to a GUI that looks somewhat decent (correct window colors, font smoothing, high DPI handling, etc). Even the default font ends up being a terrible looking bitmapped font rather than the more modern system default; we needed to manually retrieve the system default and set it as the font to use, which was a bit surprising!
We have a set of traits to facilitate creating custom window classes and managing associated window data of class instances. We also have wrapper types to properly manage the lifetimes of handles and perform type conversions (mainly String to null-terminated wide strings and back) as an extra layer of safety around the API.
macOS (Cocoa/AppKit)
The macOS implementation had its tricky parts, as overwhelmingly macOS GUIs are written with XCode and there’s a lot of automated and generated portions (such as nibs). We again use bindgen to generate Rust bindings, this time for the Objective-C APIs in macOS framework headers.
Unlike Windows and GTK, you don’t get keyboard shortcuts like Cmd-C, Cmd-Q, etc, for free if creating a GUI without e.g. XCode (which generates it for you as part of a new project template). To have these typical shortcuts that users expect, we needed to manually implement the application main menu (which is what governs keyboard shortcuts). We also had to handle runtime setup like creating Objective-C autorelease pools, bringing the window and application (which are separate concepts) to the foreground, etc. Even implementing invoke to call a function on the main thread had its nuances, since modal windows use a nested event loop which would not call queued functions under the default NSRunLoop mode.
We wrote some simple helper types and a macro to make it easy to implement, register, and create Objective-C classes from Rust code. We used this for creating delegate classes as well as subclassing some controls for the implementation (like NSButton); it made it easy to safely manage the memory of Rust values underlying the classes and correctly register class method selectors.
The Test UI
We’ll discuss testing in the next section. Our testing UI is very simple. It doesn’t create a GUI, but allows us to interact directly with the model. The ui! macro supports an extra piece of syntax when tests are enabled to optionally set a string identifier for each element. We use these strings in unit tests to access and interact with the UI. The data binding types also support a few additional methods in tests to easily manipulate values. This UI allows us to simulate button presses, field entry, etc, to ensure that other UI state changes as expected as well as simulating the system side effects.
Mocking and Testing
An important goal of our rewrite was to add tests to the crash reporter; our old code was sorely lacking them (in part because unit testing GUIs is notoriously difficult).
Mocking Everything
In the new code, we can mock the crash reporter regardless of whether we are running tests or not (though it is always mocked for tests). This is important because mocking allows us to (manually) run the GUI in various states to check that the GUI implementations are correct and render well. Our mocking not only mocks the inputs to the crash reporter (environment variables, command line parameters, etc), it also mocks all side-effectful std functions.
We accomplish this by having a std module in the crate, and using crate::std throughout the rest of the code. When mocking is disabled, crate::std is simply the same as ::std. But when it is enabled, a bunch of functions that we have written are used instead. These mock the filesystem, environment, launching external commands, and other side effects. Importantly, only the minimal amount to mock the existing functions is implemented, so that if e.g. some new functions from std::fs, std::net, etc. are used, the crate will fail to compile with mocking enabled (so that we don’t miss any side effects). This might sound like a lot of effort, but you might be surprised at how little of std really needed to be mocked, and most implementations were pretty straightforward.
Now that we have our code using different mocked functions, we need to have a way of injecting the desired mock data (both in tests and in our normal mocked operation). For example, we have the ability to return some data when a File is read, but we need to be able to set that data differently for tests. Without going into too much detail, we accomplish this using a thread-local store of mock data. This way, we don’t need to change any code to accommodate the mock data; we only need to make changes where we set and retrieve it. The programming language enthusiasts out there may recognize this as a form of dynamic scoping. The implementation allows our mock data to be set with code like
mock::builder()
.set(
crate::std::env::MockCurrentExe,
"work_dir/crashreporter".into(),
)
.run(|| crash_reporter_main())
in tests, and
pub fn current_exe() -> std::io::Result {
Ok(MockCurrentExe.get(|r| r.clone()))
}
in our crate::std::env implementation.
Testing
With our mocking setup and test UI, we are able to extensively test the behavior of the crash reporter. The “last mile” of this testing which we can’t automate easily is whether each UI implementation faithfully represents the UI model. We manually test this with a mocked GUI for each platform.
Besides that, we are able to automatically test how arbitrary UI interactions cause the crash reporter to affect its own UI state and the environment (checking which programs are invoked and network connections are made, what happens if they fail, succeed, or timeout, etc). We also set up a mock filesystem and add assertions in various scenarios over the precise resulting filesystem state once the crash reporter completes. This greatly increases our confidence in the current behaviors and ensures that future changes will not alter them, which is of the utmost importance for such an essential component of our crash reporting pipeline.
The End Product
Of course we can’t get away with writing all of this without a picture of the crash reporter! This is what it looks like on Linux using GTK. The other GUI implementations look the same but styled with a native look and feel.
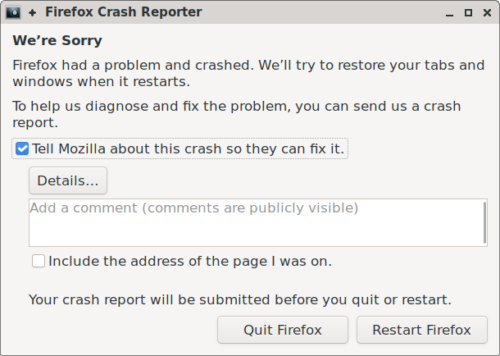
Note that, for now, we wanted to keep it looking exactly the same as it previously did. So if you are unfortunate enough to see it, it shouldn’t appear as if anything has changed!
With a new, cleaned up crash reporter, we can finally unblock a number of feature requests and bug reports, such as:
We are excited to iterate and improve further on crash reporter functionality. But ultimately it’d be wonderful if you never see or use it, and we are constantly working toward that goal!
The post Porting a cross-platform GUI application to Rust appeared first on Mozilla Hacks - the Web developer blog.







 <figcaption class="wp-element-caption">Credit: Getty Images for the Webby Awards</figcaption>
<figcaption class="wp-element-caption">Credit: Getty Images for the Webby Awards</figcaption> <figcaption class="wp-element-caption">Kara Swisher accepts her Webby Lifetime Achievement Award. Credit: Getty Images for the Webby Awards</figcaption>
<figcaption class="wp-element-caption">Kara Swisher accepts her Webby Lifetime Achievement Award. Credit: Getty Images for the Webby Awards</figcaption> <figcaption class="wp-element-caption">Keke Palmer accepts the Webby Award for Special Achievement. Credit: Getty Images for the Webby Awards</figcaption>
<figcaption class="wp-element-caption">Keke Palmer accepts the Webby Award for Special Achievement. Credit: Getty Images for the Webby Awards</figcaption> <figcaption class="wp-element-caption">Julia Louis-Dreyfus accepts the Webby Podcast of the Year Award. Credit: Getty Images for the Webby Awards</figcaption>
<figcaption class="wp-element-caption">Julia Louis-Dreyfus accepts the Webby Podcast of the Year Award. Credit: Getty Images for the Webby Awards</figcaption> <figcaption class="wp-element-caption">Shannon Sharpe accepts his Webby Advocate of the Year Award. Credit: Getty Images for the Webby Awards</figcaption>
<figcaption class="wp-element-caption">Shannon Sharpe accepts his Webby Advocate of the Year Award. Credit: Getty Images for the Webby Awards</figcaption> <figcaption class="wp-element-caption">Creator Abi Marquez accepts her Webby Award. Credit: Getty Images for the Webby Awards</figcaption>
<figcaption class="wp-element-caption">Creator Abi Marquez accepts her Webby Award. Credit: Getty Images for the Webby Awards</figcaption> <figcaption class="wp-element-caption">Raphael Mimoun at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Raphael Mimoun at Mozilla’s Rise25 award ceremony in October 2023.</figcaption> <figcaption class="wp-element-caption">Keoni Mahelona at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Keoni Mahelona at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>


 <figcaption class="wp-element-caption">Julia Janssen at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Julia Janssen at Mozilla’s Rise25 award ceremony in October 2023.</figcaption> <figcaption class="wp-element-caption">Abbie Richards at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Abbie Richards at Mozilla’s Rise25 award ceremony in October 2023.</figcaption> The new open ecosystem of extensions on Firefox for Android
The new open ecosystem of extensions on Firefox for Android 





 <figcaption>Firefox illustration by UX designer
<figcaption>Firefox illustration by UX designer  <figcaption>Team members during the workshop</figcaption>
<figcaption>Team members during the workshop</figcaption> <figcaption>One group’s draft statement from Step 3</figcaption>
<figcaption>One group’s draft statement from Step 3</figcaption>





 ) for us to reproduce the issue and come up with a
) for us to reproduce the issue and come up with a